
Има ли грешка, има и прощка. Ако сте открили нещо нередно тук, значи и вие имате погледа на коректор. Във времената, когато все по-малко медии и дори издателства се доверяват на специалисти, които да следят за правописа, дали пък изкуственият интелект (ИИ) няма да се окаже полезен помощник? Време е за един показателен правописен експеримент.
„Как се пише?“ е въпрос, на който Павлина Върбанова помага на българите да си отговорят вече десетилетие и половина. В „Дигитални истории“ пък Георги Караманев търси различни гледни точки към напредъка на ИИ – след негов експеримент генерирани стихове попаднаха в топ 10 на два поредни поетични конкурса, а неотдавна провери колко биха изкарали най-модерните ИИ модели на матурата по български език и литература.
ИИ безспорно е голямата новина на днешния ден. И докато той е способен на все повече чудеса, ние продължаваме да търсим ежедневните приложения, в които технологията може да помогне, да облекчи... дори да ни замени.
Всички (надяваме се) вярваме, че по правописа, а не по дрехите днес посрещат онлайн. В технологичната епоха общуваме все по-често чрез писмени текстове и начинът, по който го правим, определено издава толкова много на събеседника. Може ли ИИ да ни помогне да пишем грамотно?
Павлина и Георги ще се опитат да проверят възможно най-безпристрастно чрез своя експеримент.
Човешко е да се греши...
Нали уж ИИ все повече заприличва на нас и нищо човешко не му е чуждо? Да видим как се справя в „стресова“ ситуация – с медиен текст, в който нарочно залагаме 30 грешки от всякакъв характер: правописни, граматични, пунктуационни, лексикални.
Министър Генов заяви, че сигналите са от средата на миналата година, но регионалните инспекций разполагат с малко хора, затова проверката на „250 сигнали е изключително непосилен труд.“ Той настоя, обаче, че всички сигнали се проверяват.
Министърът каза, че някои фирми, например занимаващи се с интернет търговия_ не са обхванати с тези продуктови такси. „Много сме мислели какво можем да направим съвместно с Националната Агенция за Приходите. Имаме виждания, предстоят срещи с министерство на финансите по този въпрос, за да измислим подходящо законодателство,“ каза министъра на екологията.
Според Генов, продуктовите такси, които се събират в момента_ са символични. Като един от проблемите с еко таксите, той посочи остарялата наредба към закона за управление на отпадъците, определяща размера на продуктовите такси в България. Същевременно Генов е на мнение, че операторите са решили да вдигнат цените благодарение на повишаването на проверките през последните месеци от страна на еко министерството. Той посочи, че операторите на продуктовите такси са създадени, така че да не могат да формират печалба, а „всички пари да бъдат вложени в оползотворяването на тези отпадъци.“
После включваме най-модерните модели ИИ. Важен нюанс за технологичните любители: използваме моделите, които сме избрали, не през потребителски интерфейс и личен профил, а през програмен интерфейс, така че резултатите да не се влияят от предишните ни взаимодействия с моделите. За да е още по-пълноценен експериментът, на всеки модел подаваме по две задания (промптове). С първото просто молим текстът да бъде коригиран и да получим обяснение защо е направена дадена корекция. Второто задание е значително по-подробно и го създаваме след няколко „разговора“ с ИИ. Използваме техника, наречена meta-prompting – даваме съставени от нас указания на GPT-4o, който да ги развие и прецизира. В резултат се получава задание, което е по-дълго дори от самия текст. (Означаваме кратките задания с LP, а дългите – с SP.) В единия опит имаме просто „случаен изстрел“, в другия пробваме дали конкретни указания ще подобрят резултата. Дали наистина ще има разлика?
За участие в теста избираме два от моделите в платената версия на ChatGPT – GPT-4o и о3. Тук са Claude 4 Opus на Anthropic и флагманът на Google – Gemini 2.5 Pro. Всички те са платени, единствено последният има ограничен брой свободни заявки.
За пъстрота добавяме българския BgGPT и безплатната версия на ChatGPT. Важно е да отбележим, че използваме популярните големи езикови модели, никой от които не е обучен толкова добре на български език, нито пък е „специализиран“ в такава специфична роля като коректорската. Даваме на всички само по един шанс. Затова в таблицата с резултатите няма да видите GPT-4o (LP) – при тази заявка моделът просто върна малка част от текста.
Електронният коректор
Ето че пускаме заявките, след секунди получаваме отговорите, събираме резултатите... и се оказва, че трудностите тепърва започват. Как да преценим дали всички грешки са коригирани, ако например моделът е редактирал текста и е избегнал конкретната правописна неточност? Какво правим, ако добави, вместо да поправи грешки? Трябва ли да го стимулираме с допълнителни точки, ако е открил място в текста, което си струва да бъде „загладено“, дори да не става дума за явна грешка? Ще му прощаваме ли, ако просто промени вида на кавичките?
Опитваме се да бъдем максимално безпристрастни и така събираме резултатите в подробна таблица. Ето как се справиха моделите с конкретните задачи.
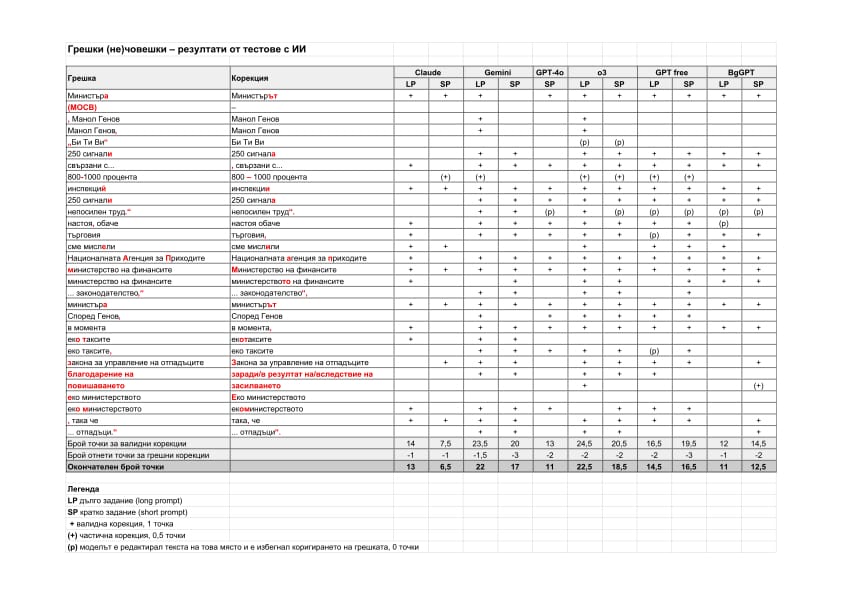
Грешки, които (почти) всички модели откриха
Едва ли ще бъде изненада, че формата инспекций не се изплъзна от ничий поглед – все пак очакваме ИИ да се справя минимум на ниво автоматична коригираща програма. И на двете места, където думата министър беше погрешно написана с кратък член, това беше поправено надлежно от всички, ако пренебрегнем, че Gemini (SP) реши изобщо да не членува думата в самото начало на текста: Министър на околната среда...¹ Приятно сме впечатлени, че ИИ се ориентира в синтактичната служба на думите, когато това е от значение за правописа, но и грешките са тривиални, затова би било пресилено да заключим, че владее добре правилата за поставяне на пълен и кратък член.
Всички модели отчетоха липсата на главна буква в министерство на финансите и само с едно изключение (Claude SP) поправиха Националната Агенция за Приходите на Националната агенция за приходите, тоест приложиха правилото за правописа на съставните собствени имена.
В областта на пунктуацията ИИ забеляза липсващата запетая в началото на обособената част свързани с продуктовите такси за черна и бяла техника, която несъмнено много хора биха поставили дори и интуитивно, но далеч не толкова много биха се сетили за затварящата запетая в края на подчиненото изречение които се събират в момента².
Грешки, които никой модел не забеляза
Да, признаваме си, че бяхме взискателни и с някои грешки вдигнахме летвата високо. Но как иначе ще разберем колко може ИИ? Уви, той изобщо не отчете неуместното съкращение МОСВ, което се употребява за Министерството на околната среда и водите, но не и за министъра.
Нито един модел не премахна кавичките при Би Ти Ви. За да сме пунктуални, уточняваме: липсва изрично правило, че при собствени имена, които се състоят от названия на букви, не се поставят кавички. Засега кодификаторът ни е дал само примери във връзка с друго правило.
Думата еко министерство следва да се пише слято и това е отчетено от повечето модели, но никой от тях не се е сетил да замени малката буква с главна. Освен професионалните коректори вероятно малко хора биха го направили. А е редно, защото, когато дадено съставно собствено име се съкращава или се перифразира, главната буква се запазва, например Министерство на външните работи – Външно министерство.
При 800-1000 процента половината модели са заменили малкото тире с дълго, но нито един не е оставил интервали, както е редно според официалните правописни правила: 800 – 1000 процента.
Какво още мина под радара?
Двете излишни запетаи, ограждащи името Манол Генов в началото на текста, бяха премахнати единствено от Gemini (LP) и o3 (LP). Пунктуацията при цитиране също затруднява ИИ, макар че точно тук правилото е формално: щом цитатът е вмъкнат в авторово изречение, кавичките се затварят пред точката. Около половината от моделите не са поправили грешката и в трите случая.
Слятото, полуслятото и разделното писане в българския език са предизвикателство и за хората, и за ИИ. Само Gemini (LP и SP) са се справили със сливането на еко таксите в екотаксите и на еко министерството в екоминистерството. Непоследователно действат Claude (SP), GPT-4o (SP), o3 (SP), o3 free (LP и SP), които са коригирали едната грешка и са подминали другата, при положение че те са еднотипни. Осмеляваме се да мислим, че в сравнение с ИИ по-вероятно е човешкият интелект или да коригира двете грешки, или да не ги регистрира.
Освен правописни, пунктуационни и граматични грешки, заложихме и две лексикални – неточно употребени думи. Едната (благодарение на) беше уловена от половината модели и вместо ние да обясняваме, даваме думата на Gemini (LP): „Предлогът „благодарение на“³ има положителна конотация и не е подходящ за описване на негативно събитие (вдигане на цени).“ Моделът дори ни предлага два варианта за заместване – и двата сполучливи: вследствие на и поради. Другите справили се със задачата заменят неподходящия предлог със заради и в резултат на.
Втората лексикална грешка е при употребата на повишаване в съчетание с проверки. Просто проверките не се повишават. Само два модела са забелязали това: o3 (LP) е заменил думата със засилването и това според нас е сполучливо, а BgGPT (SP) – с увеличаването, за което сме му присъдили половин, а не цяла точка⁴.
Потвърдено: ИИ халюцинира
Понякога ИИ си въобразява, както знаем. Оказва се, че може да си измисля и грешки, след което, естествено, се чувства задължен да ги коригира. Няколко модела (Gemini (LP и SP) GPT -4o (SP), o3 (LP и SP), GPT free (SP) са добавили запетая след например, която е излишна – в случая с тази дума се въвежда обособената част например занимаващи се с интернет търговия. Дори и въпросната дума да беше употребена като вметната част, тя е от онези, които не се ограждат със запетаи.
Необяснимо защо някои модели са премахнали отварящите и затварящите кавички при първия цитат в текста, но при другите два цитата са ги оставили. Възможно е цифрите в началото на цитата (250) да са объркали ИИ. Явно първият цитат го смущава, защото там наблюдаваме и други решения, заради които сме го санкционирали с отнети точки: скъсяване на цитата чрез преместване на отварящите или затварящите кавички; промяна на съгласуването, което води до граматическа грешка: проверката на „250 сигнали са изключително непосилен труд.“
Обобщени впечатления
22,5 от максималните 30 точки получи победителят o3 (LP), а само на половин точка след него е Gemini (LP). Най-слабо представилите се модели като цяло са успели да покрият минимум 1/3 от грешките. Доста сериозна е разликата в представянето и заради различните задания – когато получат по-дълъг и прецизен промпт, моделите се представят значително по-успешно. С две изключения – GPT free и BgGPT – вероятно защото като по-малки модели по-трудно могат да навлизат в дълбок контекст.
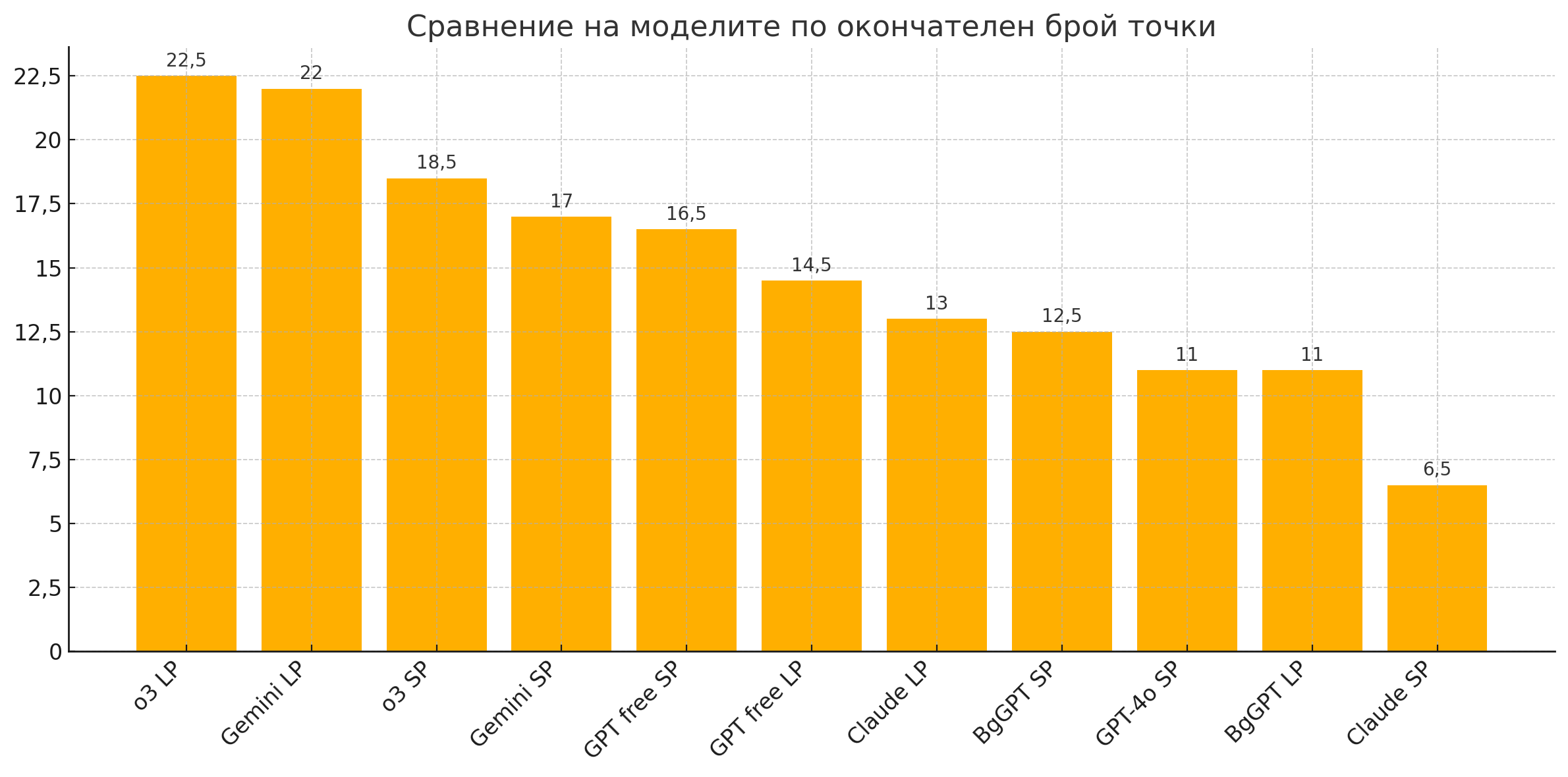
Сигурни сме, че всеки може да направи своите изводи, да прецени доколко добре се справя ИИ с българския правопис, граматика и пунктуация и дали си струва да му се довери в тази роля. Ако нещо е сигурно, то е, че моделите са далеч от това да изпълняват ролята на опитен и добър коректор, толкова дефицитна, важна и често липсваща, уви, в българските медийни среди.
Ето накратко личните впечатления на всеки от нас.
Правописно и лично
Павлина Върбанова: Признавам, че преди да направим експеримента, бях по-скептично настроена за коректорския капацитет на ИИ. Приятно съм изненадана, че поправи доста неформални грешки (например запетаята при така че), тоест в някаква степен той е започнал да „разбира“ текстовете. И това – при положение че не е специално обучаван да действа като коректор.
На сегашния етап ИИ може да се ползва като помощник за поправяне на грешки в сравнително кратки текстове, но без да му се възлагат отговорни задачи, а по-скоро за да посочи проблемни места, които са се изплъзнали от вниманието на пишещия. Възможно е ИИ да ви подведе и да предложи грешна корекция; също така при еднотипни или дори при еднакви грешки да поправи едната и да пропусне другата. Затова бъдете бдителни! В анализа наблегнахме на слабите места, за да заострим вниманието ви, а не за да ви откажем изцяло от коректорските услуги на ИИ.
Георги Караманев: Смятам, че моделите се представиха доста силно и откриха грешки, които лично аз бих пропуснал. Вижда се още нещо важно – как точното, прецизно задание сериозно подобрява резултатите. Според мен това е и ясен знак, че може да ги използваме в ежедневието. Разбира се, с едно наум. Те със сигурност могат да направят по-грамотни текстовете на огромна част от пишещите в мрежата и дори в общественото пространство.
В работата си и аз ги използвам в тази роля. Сайтът ми „Дигитални истории“ е изцяло некомерсиален, затова не мога да си позволя редактор или коректор (нещо, което искрено ми липсва от времената на традиционните печатни медии) и ИИ помага с идеи за корекции на всеки текст. Всяка от тях обаче преценявам аз, разбира се, и такъв би бил съветът ми към читателите. Така е и с почти всяко от безбройните приложения на технологията. Нещо повече – всеки нов идва с нови възможности, както личи от нашия анализ (а и от „представянето“ на ИИ на матурата по български език и литература).
Експериментирайте, опитвайте. Доверявайте, но... проверявайте. ИИ е тук, за да остане, и си струва да се възползваме от всяка следваща негова впечатляваща възможност.
2 Само Claude (SP) не отчете и двете грешки.
3 Наистина благодарение на е сложен предлог.
4 Увеличава се броят на проверките, а не самите проверки, затова този вариант не е съвсем точен.
Езикът може да е вкусен и извън блюдото – онзи, българският език, на който говорим от малки и на който около 24 май се кълнем в обич. А той в същността си е средство за общуване и за да ни служи добре, непрекъснато се променя. Да го погледнем в неговата динамика и да се опитаме да разберем какво става и защо, кои са движещите механизми и как те са свързани с обществените процеси. И тъй като задачата не е лека, ще го правим постепенно – на порции.
„Тоест“ се издържа единствено от читателски дарения
Ако харесвате нашата работа и искате да продължим, включете се с месечно дарение.
Подкрепете ни